算法白话总结
- 参考: https://programmercarl.com/
- 推荐参考本博客总结的 algo_newbie , 和本文对照着看
概绍
本群的每日刷题打卡活动, 按照 GitHub 49k star的项目 https://github.com/youngyangyang04/leetcode-master 的刷题顺序.
跟着群里有个伴一起刷题或许更容易坚持达成每日一题的目标. 做完题目之后可以在群里的小程序”今日leetcode刷题打卡”里打卡.
- 网页版: 代码随想录 https://programmercarl.com/
- 本博客只记录那些有明显自我疑问而<<代码随想录>>没有说明清楚的题目, 会标识出来并注释
本文完整参考代码
https://github.com/no5ix/no5ix.github.io/blob/source/source/code/test_algo_na.java
Java常用接口和实现
值传递
- 记住:Java 中只有值传递!只是对于对象类型,值是对象的引用地址,这使得我们可以修改对象的内容,但不能改变对象的引用本身。
- • 基本数据类型: 方法接收变量的值,修改不会影响原始变量。
- • 对象类型:
- 方法接收的是对象引用的副本,可以通过引用修改对象内容。
- 方法不能改变引用本身的指向。
1 | // 解释:在 changeReference 方法中,person 被赋值为一个新的对象,但这只是改变了方法内的 person 引用,并不影响 main 方法中 p 的引用。 |
排序
普通递增排序:
1 | // Arrays.sort 用于对数组进行排序(primitive 或 Object 类型)。 |
举例说明自定义数字排序规则 (这个排序逻辑首先按列 col 排序,如果列相同,则按行 row 排序,再根据节点的值进行排序。排序优先级依次是:列、行、值):
1 | // : List to store nodes with their column, row, and value |
举例说明自定义字幕排序规则 (比如有个 List
1 | import java.util.*; |
Map
1 | Map<Integer, Integer> map = new HashMap<>(); |
Set
1 | Set<Integer> set = new HashSet<>(); |
List
1 | List<Integer> list = new ArrayList<>(); |
Queue
1 | Queue<Integer> queue = new ArrayDeque<>(); // 不要用 LinkedList(除非你要往队列里插入null, 因为ArrayDeque不准插入null, 但是LinkedList可以), ArrayDeque用circular buffer实现的, 是最高效的: https://stackoverflow.com/questions/6129805/what-is-the-fastest-java-collection-with-the-basic-functionality-of-a-queue |
Deque
1 | Deque<Integer> deque = new ArrayDeque<>(); // 不要用 LinkedList(除非你要往队列里插入null, 因为ArrayDeque不准插入null, 但是LinkedList可以), ArrayDeque用circular buffer实现的, 是最高效的: https://stackoverflow.com/questions/6129805/what-is-the-fastest-java-collection-with-the-basic-functionality-of-a-queue |
Stack
1 | Stack<Integer> stack = new Stack<>(); |
String
1 | String string = " testString "; |
数组
lc704 - 二分查找 - 20240814
1 | class Solution { |
二分查找扩展题 - lc69 - 求平方
1 | class Solution { |
lc27
- https://programmercarl.com/0027.移除元素.html#算法公开课
- https://leetcode.com/problems/remove-element/description/
双指针法(快慢指针法): 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
定义快慢指针:
- 快指针:寻找新数组的元素 ,新数组就是不含有目标元素的数组
- 慢指针:指向更新 新数组下标的位置
诀窍: 应该想象成 slowIndex 之前的那些数组格子就是新的数组
1 | class Solution { |
lc977 - 有序数组的平方 - 20240916
- https://programmercarl.com/0977.有序数组的平方.html#算法公开课
- https://leetcode.com/problems/squares-of-a-sorted-array/description/
1 | class Solution { // lc977 |
链表
lc206 - 链表反转
- https://programmercarl.com/0206.翻转链表.html#算法公开课
https://leetcode.com/problems/reverse-linked-list/description/
重要!!!!! 记忆口诀: 举一反(反转)三(3个指针! pre! cur! temp!)
- 核心要点就是需要保存一个后面可能要用的结点就弄一个指针出来, 比如这个pre
1 | // 双指针 |
lc24 - 两两交换链表中的节点
- https://programmercarl.com/0024.两两交换链表中的节点.html
重要!!!!! 记忆口诀(和反转链表很类似): 举一(1个dummyHead指针!)反(反转)三(3个指针! cur! node1! node2!)
- 核心要点(和反转链表很类似): 就是需要保存一个后面可能要用的结点就弄一个指针出来, 需要两个就弄两个指针, 比如这个node1, node2 !!
1 | // 将步骤 2,3 交换顺序,这样不用定义 temp 节点 |
哈希表
lc15 - 3Sum
其实这道题目使用哈希法并不十分合适(4sum就没办法了),因为在去重的操作中有很多细节需要注意,在面试中很难直接写出没有bug的代码。
接下来我来介绍另一个解法:双指针法(4sum也是这种思路),这道题目使用双指针法 要比哈希法高效一些,那么来讲解一下具体实现的思路。
1 | class Solution { |
lc18 - 4Sum
1 | class Solution { |
字符串
lc28 - 实现strStr() - 20240923
暴力解法-掌握这个暴力解法即可
1 | class Solution { |
KMP不要求-面试基本不会出的-背代码就没意思了
- https://programmercarl.com/0028.实现strStr.html#算法公开课
- https://leetcode.com/problems/find-the-index-of-the-first-occurrence-in-a-string/
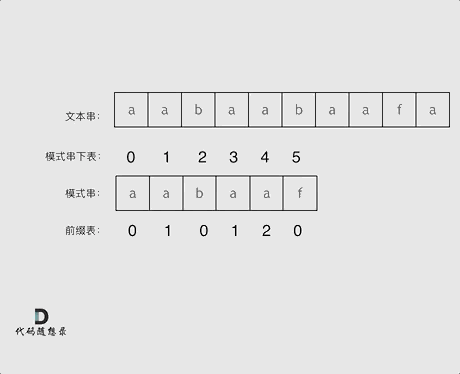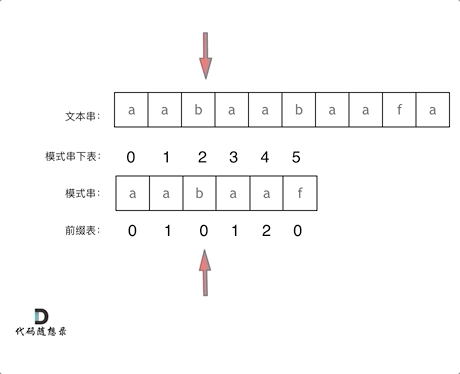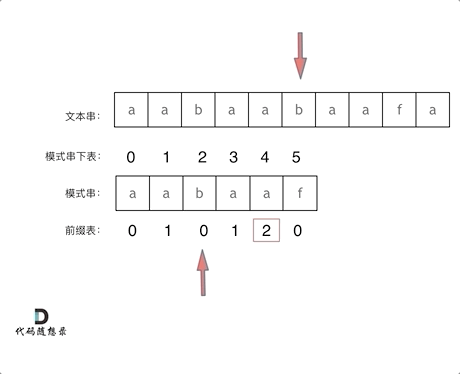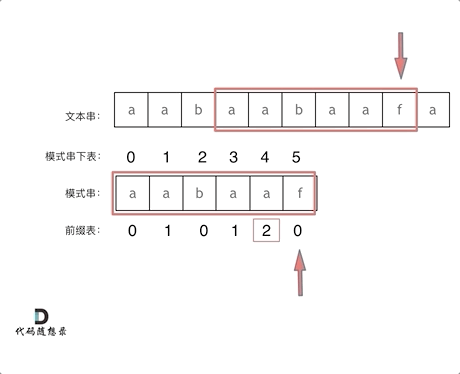
看一下如何利用 前缀表找到 当字符不匹配的时候应该指针应该移动的位置。如上动画所示:
找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
为什么要前一个字符的前缀表的数值呢,因为要找前面字符串的最长相同的前缀和后缀。
所以要看前一位的 前缀表的数值。
前一个字符的前缀表的数值是2, 所以把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
最后就在文本串中找到了和模式串匹配的子串了。
1 | class Solution { |
lc459 - 重复的子字符串-暴力解法-掌握这个暴力解法即可
- https://programmercarl.com/0459.重复的子字符串.html#算法公开课
- https://leetcode.com/problems/repeated-substring-pattern/
1 | // 作者:力扣官方题解 |
栈与队列
lc239 - Sliding Window Maximum
- https://programmercarl.com/0239.滑动窗口最大值.html#其他语言版本
- https://leetcode.com/problems/sliding-window-maximum/
1 | //利用双端队列手动实现单调队列 |
lc347 - Top K Frequent Elements
- https://leetcode.com/problems/top-k-frequent-elements/description/
- https://programmercarl.com/0347.前K个高频元素.html#其他语言版本
- Similar problem: https://leetcode.com/problems/kth-largest-element-in-an-array/
We should solve this kind of top-level problem using the “Quick Select” approach (it’s very similar to Quick Sort). Because its time complexity of O(n) is lower, this method is more efficient than the Heap-based approach with a time complexity of O(nlogn).
Referenced this: https://www.bilibili.com/video/BV1Bz4y117Fr/
- 时间复杂度:O(N),其中 N 为数组的长度。
设处理长度为 N 的数组的时间复杂度为 f(N)。由于处理的过程包括一次遍历和一次子分支的递归,最好情况下,有 f(N)=O(N)+f(N/2),根据 主定理,能够得到 f(N)=O(N)。 - 最坏情况下,每次取的中枢数组的元素都位于数组的两端,时间复杂度退化为 O(N)。但由于我们在每次递归的开始会先随机选取中枢元素,故出现最坏情况的概率很低。
- 平均情况下,时间复杂度为 O(N)。
- 空间复杂度:O(N)。哈希表的大小为 O(N),用于排序的数组的大小也为 O(N),快速排序的空间复杂度最好情况为 O(logN),最坏情况为 O(N)。
1 | import java.util.Map; |
二叉树
二叉树递归解法的写法窍门
再来看返回值,递归函数什么时候需要返回值?什么时候不需要返回值?这里总结如下三点:
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(这种情况就是本文下半部分介绍的113.路径总和ii, https://programmercarl.com/0112.路径总和.html#相关题目推荐)
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。 (这种情况我们在236. 二叉树的最近公共祖先, https://programmercarl.com/0236.二叉树的最近公共祖先.html#算法公开课)
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(这种情况符合: https://programmercarl.com/0112.路径总和.html#算法公开课)
前序(迭代法重要, 普通二叉树常用)
.gif)
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
1 | class Solution { |
中序(迭代法重要, 二叉搜索树BST常用, 因为BST中序遍历出来是个有序的递增数组)
.gif)
中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
1 | class Solution { |
后序(迭代法不重要, 很少用到, 会前序按照以下方法就会写后序)
- 先序遍历是
中左右 - 调整代码左右循序
- 变成
中右左-> 反转result数组 ->左右中 - 后序遍历是
左右中
层序
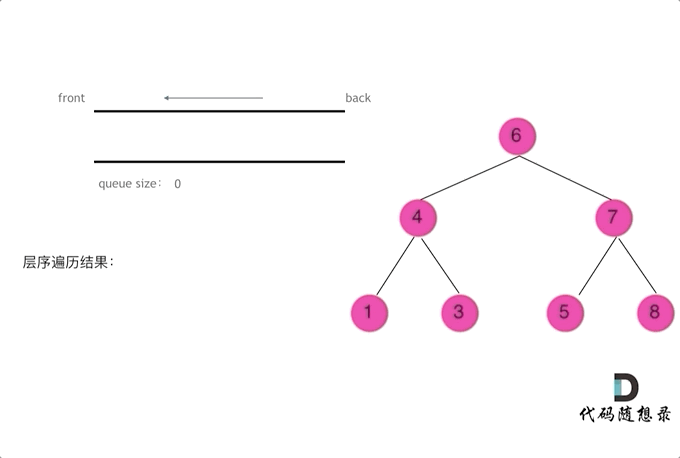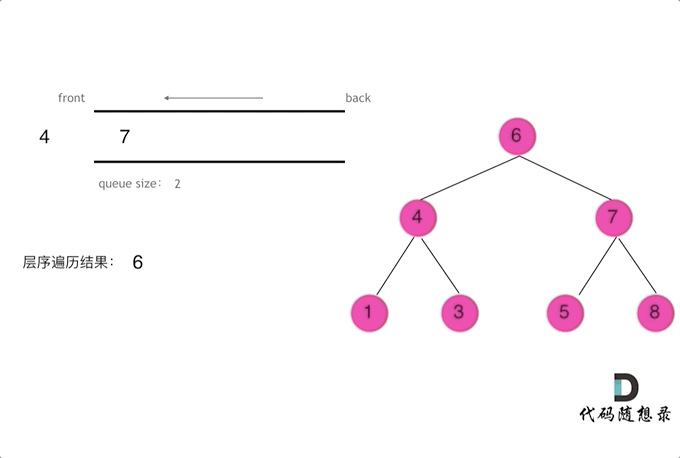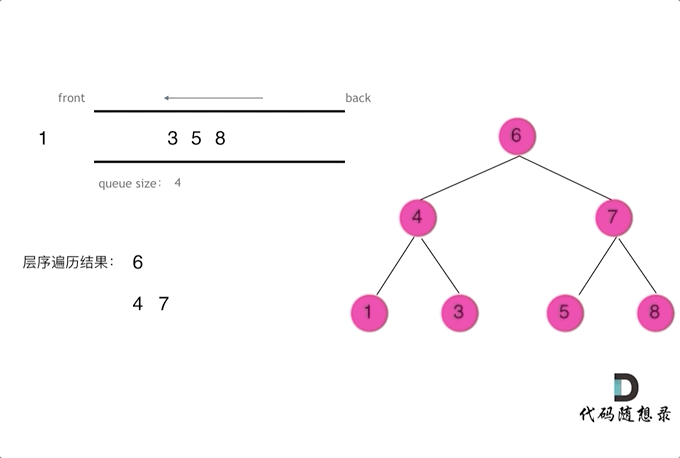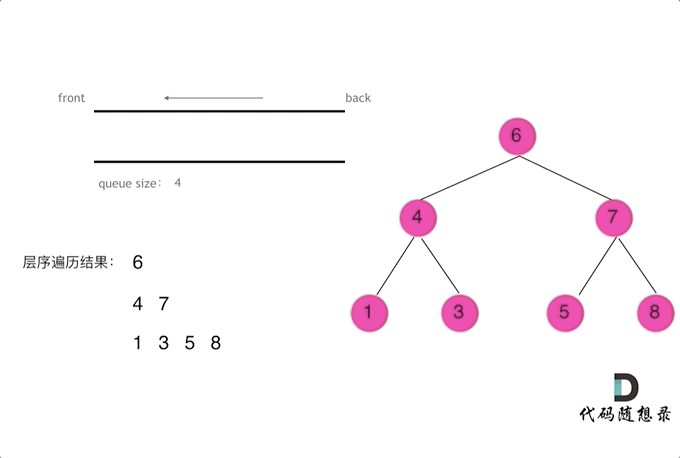
1 | class Solution { |
高度
- 二叉树节点的高度:指从
该节点到叶子节点的最长简单路径边的条数或者节点数 - 二叉树节点的深度:指从
根节点到该节点的最长简单路径边的条数或者节点数 - 根节点的高度就是二叉树的最大深度
深度
- 求深度用
层序遍历是最适合的最直观容易理解 - 二叉树的深度: 根节点到最远叶子节点的最长路径上的节点数。
- 叶子节点: 是指没有子节点的节点。
最大深度
- https://programmercarl.com/0104.二叉树的最大深度.html
- https://leetcode.com/problems/maximum-depth-of-binary-tree/
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
在二叉树中,一层一层的来遍历二叉树,记录一下遍历的层数就是二叉树的深度,
迭代法
层序遍历:
1 | class Solution { |
递归法1-回溯
掌握后可以解树的最小深度, lc111: https://leetcode.com/problems/minimum-depth-of-binary-tree/description/)
1 | class Solution { |
递归法2
后序遍历, 掌握后可以解 树的最大直径 lc543: https://leetcode.com/problems/diameter-of-binary-tree/description/):
1 | class Solution { |
最小深度
- https://programmercarl.com/0111.二叉树的最小深度.html#算法公开课
- https://leetcode.com/problems/minimum-depth-of-binary-tree/description/
最小深度: 是从根节点到最近叶子节点的最短路径上的节点数量。
迭代法
层序遍历:
1 | class Solution { |
递归法-回溯
1 | class Solution { |
二叉搜索树
- 二叉搜索树的中序遍历是个递增有序数组, 利用好这一点非常方便解题
- 二叉搜索树的迭代遍历很好写, 大多数时候用不到递归方式来解题
- 空二叉树是二叉搜索树
回溯
模板
1 | void backtracking(参数) { |
组合
没有剪枝的版本
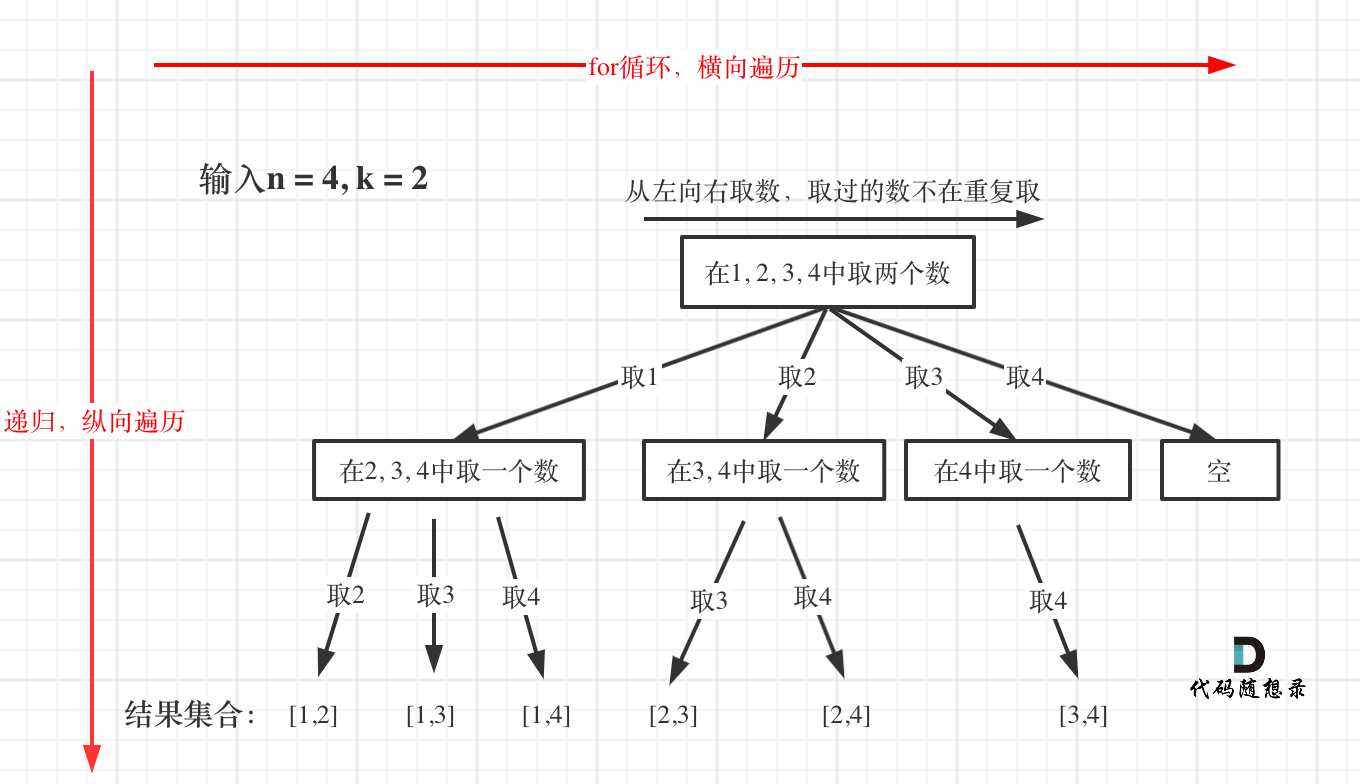
1 | class Solution { |
剪枝的版本
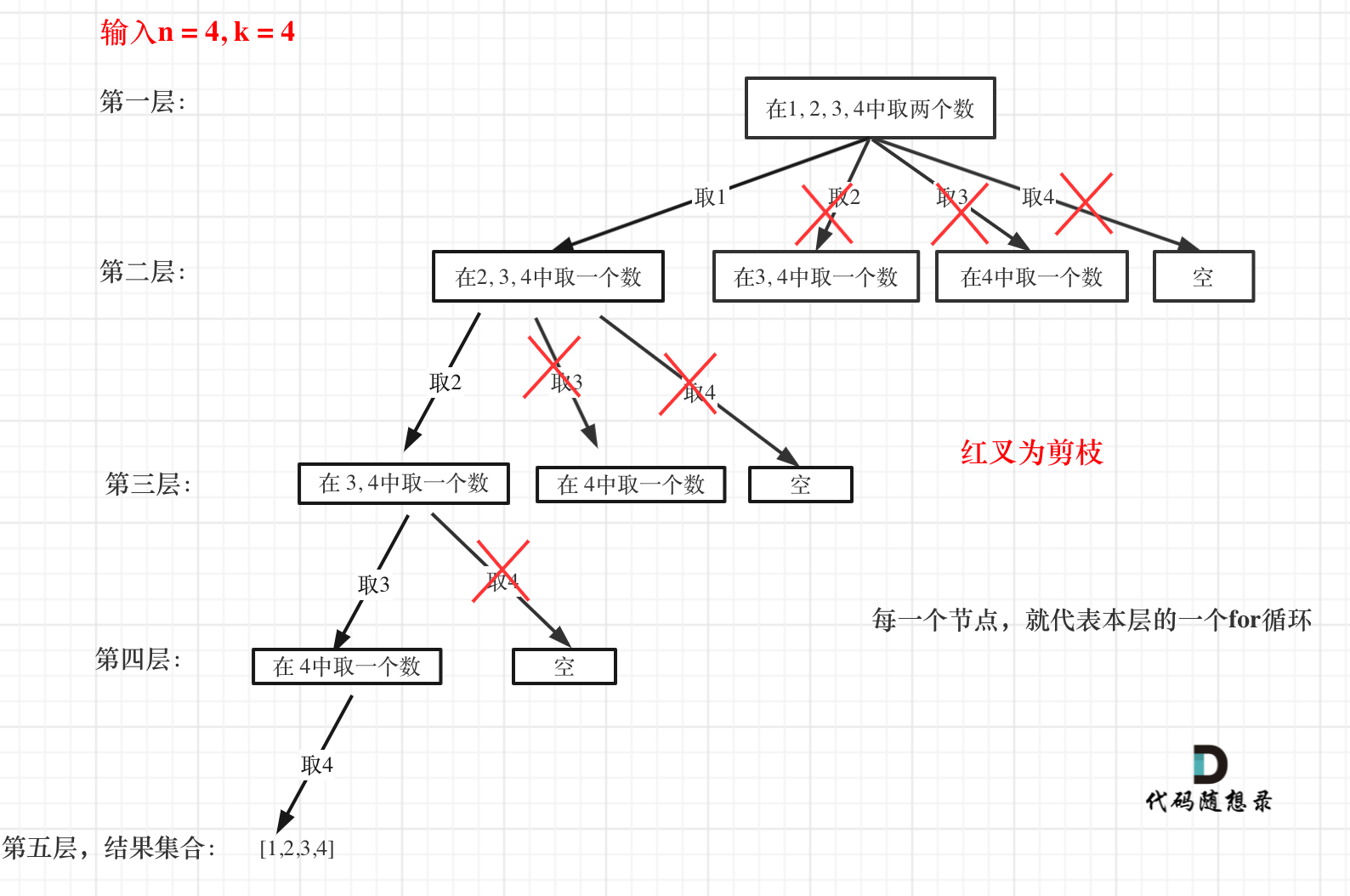
图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置。
如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了。
注意代码中i,就是for循环里选择的起始位置。
for (int i = startIndex; i <= n; i++) {
接下来看一下优化过程如下:
- 已经选择的元素个数:
path.size(); - 还需要的元素个数为:
k - path.size(); - 在集合n中i最大可以从该起始位置开始遍历 :
n - (k - path.size()) + 1(备注:n - (k - path.size())就是表示从已经最大的数n往回退几个数再开始搜索遍历, 退几个数呢? 退k - path.size()个数, 后面多出来的那个+1是因为要包括起始位置,我们要是一个左闭的集合)
那为什么 n - (k - path.size()) + 1 有个+1呢? 因为包括起始位置,我们要是一个左闭的集合。
举个例子,n = 4,k = 3, 目前已经选取的元素为0个(即path.size()为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
从2开始搜索都是合理的,可以是组合[2, 3, 4]。从”3”开始就不合理了, 因为只能[3, 4, ?], “4”后面没有了, 只有2个数字”3”和”4”能用.
这里大家想不懂的话,建议也举一个例子,就知道是不是要+1了。
所以优化之后的for循环是:
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜索的起始位置
优化后整体代码 diff 如下:
1 | class Solution { |